Armazenamento molecular de dados
Já existem propostas para armazenar dados em pó, mas a principal alternativa à atual geração de dispositivos magnéticos vinha ficando por conta do armazenamento de dados em moléculas de DNA.
Acaba de surgir uma alternativa, capaz de guardar informações de forma estável por milhões de anos - e sem gastar energia.
"Imagine armazenar o conteúdo inteiro da Biblioteca Pública de Nova York em uma colher de chá de proteína. Pelo menos nesta fase, não vemos este método competindo com os métodos existentes de armazenamento de dados. Em vez disso, vemos isto como complementar a essas tecnologias e, como objetivo inicial, adequado para o armazenamento de dados de arquivamento de longo prazo," disse Brian Cafferty, da Universidade Harvard, nos EUA.
Praticamente a totalidade do armazenamento de dados de longo prazo é feita atualmente em fitas magnéticas.
Armazenamento de dados em oligopeptídeos
Hoje já é possível sintetizar fitas de DNA para registrar qualquer informação, incluindo vídeos de gatos, tendências de dietas e tutoriais culinários - artigos científicos e relatos históricos, que devem ser guardados para a posteridade, também podem ser armazenados.
Embora a molécula de DNA seja pequena comparada aos chips de computador, ela é grande no mundo molecular. E a síntese de DNA requer mão-de-obra qualificada e muitas vezes repetitiva. Se cada mensagem precisar ser projetada do zero, o armazenamento de macromoléculas pode se tornar um trabalho demorado e caro.
Por isso Cafferty foi procurar moléculas menores.
"Partimos para explorar uma estratégia que não se baseia diretamente na biologia," conta ele. "Em vez disso, confiamos em técnicas comuns em química orgânica e analítica e desenvolvemos uma abordagem que usa moléculas pequenas e de baixo peso molecular para codificar informações."
Continua depois da publicidade |
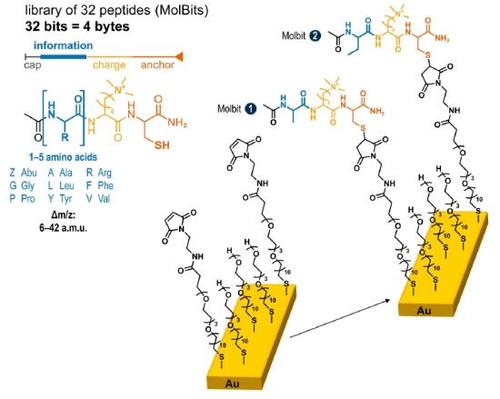
Ele encontrou o que procurava nos oligopeptídeos - dois ou mais peptídeos ligados juntos -, que são comuns, estáveis e menores do que o DNA, o RNA ou proteínas.
Os oligopeptídeos também variam em massa, dependendo do número e tipo dos aminoácidos. Misturados, eles são distinguíveis uns dos outros, como letras em uma sopa de letrinhas.
Ler e escrever quimicamente
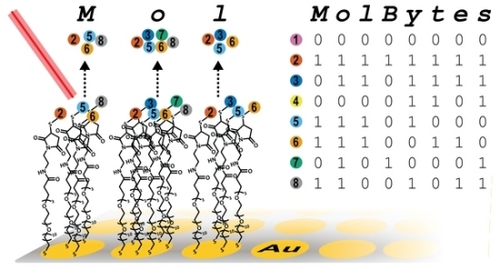
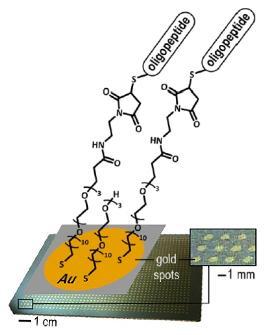
Compor palavras com as letrinhas da sopa química é um pouco complicado. Primeiro, oligopeptídeos com massas variadas - as letras - são depositados em micropoços. Cada matriz contém 384 desses minúsculos buracos. Assim como a tinta é absorvida por uma página de papel, as misturas de oligopeptídeos são então montadas em uma superfície de metal, onde podem ser armazenadas indefinidamente. Para ler o que está escrito, os poços são submetidos a um espectrômetro de massa, que classifica as moléculas por massa, o que diz quais oligopeptídeos estão presentes ou ausentes.
Para traduzir o amontoado de moléculas em letras e palavras, é usado o tradicional código binário. Um "M", por exemplo, utiliza quatro dos oito oligopeptídeos possíveis, cada um com uma massa diferente. Os quatro presentes nos poços recebem um "1", enquanto os quatro ausentes recebem um "0". O código binário molecular aponta para uma letra correspondente ou, se a informação é uma imagem, um píxel correspondente.
Com este método, uma mistura de oito oligopeptídeos pode armazenar um byte de informação; 32 podem armazenar quatro bytes; e mais poderiam armazenar ainda mais.
Até agora, Cafferty escreveu, armazenou e leu a famosa palestra do físico Richard Feynman "Há muito espaço lá embaixo", que lançou as bases da nanotecnologia, uma foto de Claude Shannon, conhecido como o pai da teoria da informação, e a Grande Onda de Kanagawa, de Hokusai.
Vantagens e desafios
No momento, a equipe consegue recuperar suas obras-primas armazenadas com 99,9% de precisão. A escrita é feita em uma velocidade média de 8 bits por segundo, enquanto a leitura chega a 20 bits por segundo.
Embora a velocidade de escrita supere em muito a escrita com DNA sintético, o sistema ainda é caro, dependendo de aparatos grandes de laboratório, o que dá a dianteira para o armazenamento de dados em DNA, que pode ser mais rápido e mais barato.
A equipe argumenta, contudo, que este é o primeiro protótipo de demonstração do conceito. Com um pouco de aprimoramento, as velocidades certamente aumentarão. Uma impressora jato de tinta, por exemplo, pode gerar microgotas a taxas de 1.000 por segundo e colocar mais informações em áreas menores. E espectrômetros de massa melhores poderão absorver ainda mais informações de cada vez.
E, ao contrário de outros sistemas de armazenamento de informações moleculares, que dependem de uma molécula específica, esta abordagem pode usar qualquer molécula maleável que possa ser manipulada em bits distinguíveis.
Cafferty lembra também que uma "nuvem química" - uma versão química da nuvem de dados atual - é uma opção estável, sem consumo de energia e resistente à corrupção de dados. Assim, se os livros queimarem, os computadores forem hackeados e os DVDs falharem, uma pastilha repleta de informações pode persistir para lembrar a humanidade do quanto já gostamos de vídeos de gatos ou de como podemos correr nas raias da insanidade espalhando notícias falsas.
